Can We Hear Differences Between A/C Power Cords? An ABX Blind Test
Introduction
On November 13, 2004, Secrets of Home Theater and High Fidelity teamed up with the Bay Area Audiophile Society (BAAS) to conduct a blind AC power cord test. The purpose of the test was to determine if a small group of volunteers could make a statistically significant differentiation of sonic differences between an assortment of generic power cords and Nordost Valhalla power cords.
The test was conducted in the living room of Casa Bellecci-Serinus in Oakland, California. The room offers 9'2" ceilings, a depth of 25'6", a front width of 37', and a rear width of 21'6". The two people acting as cable switchers, and all equipment save the speakers, were hidden behind a felt barrier that was erected between the speakers.
The test would not have been possible without the generosity of Joe Reynolds of Nordost, who supplied all the Valhalla power cords; Christine Zmuda of Parasound, who enabled us to keep the sensational Parasound Halo JC 1 monoblocks through the blind test period; Quan of Sonic Integrity, whose long-term loan of the ExactPower Power Regulator made it possible to adequately power the Parasounds; and John Baloff of Theta Digital, who loaned us their superior Carmen II transport. Mated with the Theta Gen. VIII DAC/preamp, Talon Khorus X Mk. II speakers, and Nordost Valhalla interconnects and speaker cable, this configuration supplied state-of-the-art CD sound.
Equal gratitude goes to BAAS member Manny LaCarrubba, whose patented speaker technology has been incorporated into Bang & Olufsen's Beolab 5 loudspeaker. Manny designed the test protocol, executed the set-up, created test sheets and a follow-up questionnaire, and remained remarkably composed throughout the entire proceedings. In short, the test would not have been possible without a huge amount of effort and dedication on his part.
Here are photos of Manny introducing the experiment to participants in front of the green curtain, the first set of participants, and the setup behind the curtain.



Here is how Manny describes himself:
"I've worked in one aspect or another of professional audio for all of the 20 years since I graduated college. I have a BS in Tonmeister Studies � a music and recording degree � from the State University of New York at Fredonia.
"I've worked as a recording engineer, Chief Engineer, as a staff engineer at a firm that specializes in noise and vibration control for the semiconductor industry, and for my own company designing recording studios and high end home theaters. Along the way I picked up a keen interest in loudspeaker design and have been designing speakers for over 15 years. I have several patents related to a device that provides for the uniform distribution of high frequencies from loudspeakers and is embodied in commercial products from the Danish hi-fi company Bang & Olufsen.
"I have been fortunate enough to work with gentlemen who are absolute leaders in the field of correlating objective measured performance of audio and video devices with perceived sound and visual quality. I try to make it to the papers sessions related to these fields annually at AES conventions and am at least reasonably familiar with the state of the art.
"My business partner David Moulton has conducted double blind listening tests professionally (most notably for the audibility of various data reduction schemes for digital audio), and our research to explain the sonic effects of our speaker technology has us routinely delving into the world of psychoacoustics (the study of the perception of sound quality).
"Lastly, I am currently working with a man holding a PhD. in psychometrics (the study of psychological parameters, mostly intelligence testing) on software for the analysis of standardized tests in education (which has more to do with testing audio perceptions than you might think). So, while I do not claim to be an expert in the field of psychoacoustics, I feel that I really do know more about this stuff than the average bear."
Before discussing the test protocol, it is essential to explain why we conducted the test in the first place.
Genesis of the Test
Power cords, interconnects, speaker cables, Shakti Stones, Shun Mooks, esoteric equipment supports, and the Bedini Ultraclarifier: all are bugaboos to those who believe that there must be a scientific, reproducible, and test-proof explanation for anything that claims to alter the quality of audio and video.
The fur began to fly in audio forums when this critic favorably reviewed the Bedini Dual Beam Ultraclarifier for Secrets in March of 2002. The only technical explanation provided in the review, pieced together from e-mails received from Gary Bedini, was patently inadequate. I was well aware of its shortcomings at the time, but included it because it was all that Gary had offered me. As far as I was concerned, a bulletproof technical explanation was not absolutely necessary. The proof was in the hearing.
Although my review constituted only one of the many positive raves audiophile reviewers gave the Bedini unit, my work became a target for those who dismiss "subjectivist" reviews offered without scientific proof. People seemed to comb the review for opportunities to question my hearing, integrity, and credibility.
In July of 2004, my Secrets review of Wireworld top-of-the-line speaker cable and interconnects was followed within a month by my review of the $2500 Nordost Valhalla power cords. The Secrets forum was soon abuzz. If the Bedini caused fur to fly, my one-two cable punch virtually scalped the beast.
Virtually every argument against the need for high-priced cables has ever been raised seemed to surface in short order. As dialogue developed and deteriorated, it became clear that those holding an "objectivist" viewpoint had lumped "subjectivists" and "audiophiles" into the same camp. That many audiophiles are also engineers, and that engineers design audiophile products was for the most part ignored. Even "white papers" published by audiophile companies and engineers were dismissed as bogus science. The very notion that a professional musician, music lover, and audiophile such as myself could hear differences between cables was summarily dismissed as delusional.
If one were to attempt to summarize the objectivist argument in the proverbial 100 words or less, it might read as follows: "High-priced cables are based on voodoo science, designed for gullible consumers who are so swayed by their cost, looks, and status symbol appeal that they delude themselves into believing they hear differences when such differences do not exist. The proof that the differences do not exist is that they are neither measurable nor provable in blind testing."
Manny LaCarrubba, who in the days following the test acknowledged that, "For the record, I never believed that I could hear a difference between any kind of competently made cable," uses these words to put forth the objectivist position:
"There is often a difference between human perception and reality. Galileo was famously persecuted for reporting the reality of the earth's place in the solar system. (I suspect that I will suffer the wrath of those who worship at the altar of Audiophiledom for this report.) Since Galileo, a long parade of scientists has shown us a world that is much different in reality than our perceptions suggest to us.
'It is human nature to have an opinion based on such perceptions. When someone says, 'I hear a difference between this and that,' it is an opinion.
Unfortunately, these types of opinions are often stated and assumed to be something closer to fact. Science is done with numbers. 'You got no numbers? You got nothing but opinion.'
"Does that make the person who says 'I hear a difference' a liar? Of course not! Does the fact that so many people say the same thing give the statement more credence? No! The whole world believed the earth to be the center of the universe at one time. I'm sure most of those who were current with, and knew of the work of Galileo and Copernicus, died still believing the earth was the center of everything. The point here is that it natural for us to have these perceptions, BUT, please good people, do not confuse them with reality.
"Now, why is it that our senses fail us so? A big part of this, especially when we're talking about audio, has to do with the fact that what seems straightforward and reasonable is not. It seems straightforward and reasonable to listen to a piece of audio equipment and then develop an opinion on how it sounds. Unfortunately, due to the complex way that we humans take in sensory information and then combine it with prior knowledge and experience, the resulting perception may be incorrect. If we really want to know how something sounds, we must separate out prior knowledge and visual cues and force ourselves to only use our ears. This is why we do the test blind. Our eyes play a HUGE role in our perceptions of audio quality. Counter intuitive? Yes, but true.
"Now there are perfectly good reasons to buy expensive power cords. For one they look cool. 'The better it looks, the better it sounds.' (This has been shown to be the case in studies that compare sighted to blind tests using identical equipment.) Another reason to buy them is that they cost a lot. They are status symbols. Status is good in our culture. Fear is another reason. Fear of not doing everything you can to get 'the best sound.' Of course there is plain old faith. If you believe that they make your stereo system sound better, then they do! If having them makes you feel better, makes you more relaxed when you listen to music, gives you comfort in knowing that you have left no stone unturned in your pursuit of musical enjoyment, by all means, go for it!"
What is Reality?
While I feel no need to defend my perceptions, it is important to ground accusations of subjective delusion and placebo effect in the reality of my actual review of the Nordost Valhalla power cords.
If you refer back to that review, you will discover that I initially expressed disbelief that the thin Valhalla power cords, " . . .with their transparent outer shielding and red, black, and silver innards [measuring] 7/16" thick," could trump the thick and unwieldy aftermarket power cords I was then using. I also expressed disappointment with the initial sound of the Nordost Valhalla power cords. To quote:
"Over the course of a month of use, the sound I have heard through the Valhallas progressed from flat, dull and dry to shiny bright albeit monochromatic to its current level. I remember at one point lamenting that while the top was as transparent and vibrant as all get-out, there was precious little body and bass. As you will read below, that is NOT the case once these power cords are broken in. Had I drawn conclusions based on my initial experiences with the cabling, you would be reading a very different review."
In short, I was not initially won over by either the appearance or the sound of Nordost Valhalla power cords. The opposite is true.
It goes without saying that many posts on the Secrets forum have challenged the necessity of cable and solid-state gear break-in, calling the procedure another example of voodoo science. From such a perspective, claims that the sound of the Nordost Valhallas transformed after extensive break-in would be dismissed as further proof of delusion.
Because a phenomenon cannot either be explained or proven with the science that objectivists hold up as absolute does not mean that it does not exist. If a tree falls in the forest, and no one is present, does it make a sound? If God cannot be broken down into a mathematical equation, does that mean there is no God? Has no one heard anything about Quantum Physics, which questions the existence of an absolute objective reality? And are we really so sure of ourselves that we can proclaim with absolute certainty that only what we can "prove" is real, when we still don't fully understand the evolution of the universe and human life as we know it, let alone how the human body functions?
As countless listeners and reviewers have noted, equipment that measures wonderfully does not always sound good. Conversely, equipment that does not measure well often captivates listeners accustomed to the sound of live acoustic performance. Two pieces of gear with equal measurements can sound markedly different. Does this mean that the people who hear those differences don't know what they're hearing or talking about? Does it mean that scientific measurements are at best an inadequate description of reality? Or does it suggest that there are mysteries to sound, perception, and levels of reality that human beings have yet to fully uncover, explore and understand? And if in the end there are mysteries we have only begun to comprehend and explain, are we capable of entertaining them as real, or must we continually dismiss them in favor of the black and white absolutes that seem to have paralyzed public and political debate at the start of the 21st century?
Are Blind Tests Reliable?
In the weeks preceding our test, a Secrets forum contributor guided us to a report by John Atkinson, Stereophile Editor-in-Chief, of a blind amp test the magazine had conducted in 1989 between the solid-state Adcom GFA-555 ($750) and the similarly powerful, tubed VTL 300W monoblock ($4900/pair). The complete report may be found at http://www.stereophile.com/features/113/index.html.
To quote briefly from that report:
"Nothing seems to polarize people as much as the vexed question concerning the importance of audible differences between amplifiers. If you think there are subjective differences, you're an audiophile; if you don't, you're not. And as any glance at an appropriate issue of Consumer Reports�the publication for non-audiophiles�will confirm, the established wisdom is that once the price of an amplifier or receiver crosses a certain threshold, any further improvement in sound quality becomes irrelevant, in that it puts the price up for no apparent gain. In other words, when it comes to amplification, there is such a thing as being "too" good. Yet, as a reader of this magazine, I would expect that not only have you been exposed to real subjective quality differences between amplifiers that Consumer Reports would regard as sounding identical, you have made purchasing decisions made on the basis of hearing such differences.
"It has often been said that the only way to resolve this apparent dichotomy is to use carefully controlled blind listening tests, where the listener does not know what he or she is listening to. In this manner, imaginary differences should fall away, leaving real differences that can then be correlated with objective measurements. Unfortunately, as you will have noted, for example, from David Clark's infamous blind amplifier test in Stereo Review, it seems that with such blind listening tests, all perceived subjective differences between amplifiers (apart from those due to level, absolute polarity, and amplitude-response differences) fall away. The conclusion then drawn by some observers is that, indeed, once above a certain performance threshold, amplifiers do sound alike.
"But when you have taken part in a number of these blind tests and experienced how two amplifiers you know from personal experience to sound extremely different can still fail to be identified under blind conditions, then perhaps an alternative hypothesis is called for: that the very procedure of a blind listening test can conceal small but real subjective differences. Having taken part in quite a number of such blind tests, I have become convinced of the truth in this hypothesis. Over 10 years ago, for example, I failed to distinguish a Quad 405 from a Naim NAP250 or a TVA tube amplifier in such a blind test organized by Martin Colloms. Convinced by these results of the validity in the Consumer Reports philosophy, I consequently sold my exotic and expensive Lecson power amplifier with which I had been very happy and bought a much cheaper Quad 405�the biggest mistake of my audiophile career!
"Some amplifiers which cannot be distinguished reliably under formal blind conditions do not sound similar over lengthy listening in more familiar and relaxed circumstances.
"There is also the fact that the ability to reliably hear differences between hi-fi components varies considerably from person to person . . ."
This Ain't Gonna Be Easy
After reading John Atkinson's report, I acknowledged that identifying the sonic characteristics of different power cords is much harder than differentiating between the sound of the vastly different power amps Atkinson used in his test. This would not going to be a simple test.
I also noted that the participants who fared best in Stereophile's blind amp test were reviewers with highly developed listening skills. I therefore held a three-hour Hone Your Listening Skills session at Casa Bellecci-Serinus three weeks before the actual blind test. I had no delusions that a single three-hour practice session would provide sufficient education, but it was better than nothing.
Editor's Note: The National Research Council, in Canada, conducted research that indicated untrained listeners were just as good as trained listeners at detecting differences in sound quality, so the notion of developing listening skills is not necessarily valid.
We compared the sound of transports, amps, preamps, and power cords. We even listened to the Bedini Dual Beam Ultraclarifier, using two hopefully identical copies of the same CD in order to hear differences before and after treatment. Less than half the participants in the November blind cable test attended the October practice session.
The session was not easy. The stress of listening for subtle differences resulted in people frequently leaving the room for snacks and stretching. Before the session had concluded, a good half of the participants had already bid us adieu. This did not bode well for a blind listening test conducted without breaks.
As expected, it was much easier to hear differences in sound between components than between power cords. By the time the session had concluded, I was haunted by thoughts of Marie Antoinette, who went from eating cake to the guillotine. I even spied our dog Baci Brown wagging his tail at the thought of licking pie from my face on November 13.
Protocol and Procedures
Manny LaCarrubba chose to conduct an ABX blind test. (You listen to product "A", then to product "B", then you are presented with "X", which is either "A" or "B" and you indicate which product you think it is.) Switching was between a set of the "generic" stock power cords routinely supplied with equipment and a complete set of Nordost Valhalla power cords. Cords were switched on all equipment in the chain: Power Generator, transport, DAC/preamp, and the two monoblock amplifiers.
We chose ten musical selections, intentionally varied in musical content. Each selection was repeated thrice, first using Power Cords A, then Power Cords B, finally Power Cords X. The cords used in the A and B listening sessions were always different. If A's cords were all-generic, for example, then B's were all-Nordost Valhalla, or vice versa. X was either all-generic or all-Nordost. Participants were asked to determine if X was A or B.
For generic cords, I powered the Parasound monoblocks with the same gray cords that had come with them. Whether these cords are the same or better than the Belden cords usually supplied with power amps I do not know. Generic cords for the other equipment were randomly chosen from an assortment of stock cords that came with equipment that has passed through my system over years of purchasing and reviewing. Cords on the ExactPower and Theta Gen. VIII were 14-gauge, that on the transport 18-gauge. Each generic cable was used on the same piece of equipment throughout the trials.
In each of the ten trials, the choice of which set of cords would be "A", "'B", or "X" was determined using the random function in Manny's Microsoft Excel program. Manny printed out a random ABX sequence for each of our two listening sessions and kept it in sealed envelopes until the actual test began. None of us, including Manny, knew what sequence of ABX we would use until shortly before the first musical selection was played. By the time switchers opened the envelopes, they were entirely hidden from the participants' view and had ceased talking to each other.
Because we wanted the actual sound of the cords to come through as clearly as possible, use of sound-compromising switching apparatus was rejected in favor of time-consuming manual switching. Though this resulted in a blind test rather than a double-blind test, the fact that cable switchers did not know which cords would be A, B, and X until envelopes were opened minutes before the test began, said switchers were completely hidden from view, and switchers did not create sonic and verbal cues during the procedure suggests that a double blind test would not have yielded different results.
We positioned one switcher between the two Parasounds, his back to the listeners. The other switcher sat to the side of the equipment rack. John and Manny switched in the first round, Manny and I in the second. Exactly how switchers sat mattered naught to participants, since switchers were entirely concealed behind a felt scrim secured between the speakers with the use of microphone stands.
Plans to play a boom-box during the switching process in order to conceal all sounds created by switching cords were abandoned after Manny pointed out that hearing additional music during switching would muddy participants' sonic memory. Instead, we decided to plug and unplug cords even if the same cords were returned to equipment. (In other words, if in test 3, cable set A was Nordost, cable set B was generic, and set X was also generic, we unplugged all the generic cords after the B session and then reconnected them for X). Since Nordost and generic cords rested side-by-side and were equally accessible to switchers, switching time was constant.
Sound pressure level was held constant for each trial by using the digital volume control on the Theta DAC/preamp. For the most part we were able to switch all five cords and cue the CD in about 75 seconds. During the actual test, there were at least three false starts when we discovered that only one amp was on rather than two. I doubt the delays helped matters.
Taking my cue from John Atkinson, who determined that it was much easier to determine differences listening to the complex timbres of massed choral music with orchestra than simple, monochromatic percussion, I tried to choose a variety of music that displayed contrasting timbres. The selections were:
Rachmaninoff's Symphonic Dances (RR) Track 1
Songs of the Auvergne (CBC) Track 2
Candido and Graciela (Chesky) Track 1
Christmas Regrooved (Koch) Track 8
The Art of Leontyne Price (BMG) Disc 1, Track 15
Rosa Passos & Ron Carter (Chesky) Track 3
Berlioz Requiem (Telarc) Track 4
Rokia Traore Bowmbo� (Nonesuch) Track 3
Terry Evans Puttin' It Down (JVC-XRCD) Track 7
City Folk (unpublished live folk music master recorded by Manny)
As you will read in the test results, the track on which people performed the best was from the Berlioz Requiem. This was the only selection to feature massed choral music in state-of-the-art two-channel CD sound. This confirms John Atkinson's discovery that participants in his blind amp test scored best on massed choral music.
Manny LaCarrubba and John Johnson arrived at Casa Bellecci-Serinus on November 12 for pre-test set-up. As soon as we erected the felt barrier between the speakers, I discovered that it absorbed high frequencies and dimmed the vibrancy of treble sounds. (The felt had no effect on mid and lower range). Since one of the glories of Nordost Valhalla power cords is their natural shine and transparency on top, I sensed this would make discerning differences between cords even more difficult than expected. But since none of us had the time, energy, or funds to replace the highly absorptive felt with another material that might less affect the sound, we compromised by only making the barrier high enough to block the switchers from view. It is important to note that Manny considered the effects of the felt of far less significance than the absorptive power of the bodies and clothing of test participants. Given the felt's position between the speakers, I disagree. (Editor's Note: The felt barrier was not in any way directly between either of the speakers or any of the listeners, so whatever absorption occurred, did so with room reflections - similar to acoustic absorption panels - not the direct radiation of the sound.)
The Test Itself
We divided volunteers into two test groups. The first group arrived at 11 AM, with protocol explication beginning at 11:15. We broke around 1 for food. Agreeing not to say a thing about the test, the first group welcomed members of the second group at 1:30 for joint munching. After the first group had departed, the second test began around 2 PM and ended shortly after 4 PM.
In the first test conducted by John and Manny, selections were held to 60 seconds each. Every time soprano Leontyne Price's exquisite "Depuis le jour" was cut off mid-phrase, my heart contracted. As a result, when I ran the music in the second trial, I extended a few selections up to 11 additional seconds in order to stop at the end of musical phrases. Although this extended the length of the test a bit, I hoped it would leave participants feeling more complete. If nothing else, it made me feel better.
At the start of each session, we conducted a mini-training session by playing two selections of music. Each selection was repeated twice, one with each cable set. After the switch, I led a brief discussion in which we noted the differences we heard. The selections used in training session were not the same selections used in the test.
The short training session for the first group was conducted with the felt down. (We left the felt up for the entire second session, including the training period). With the felt down, I personally thought the differences between the sound of the two sets of cords was quite apparent, and several participants agreed with me. Once the felt was up, it was harder for me to tell the difference between the sound of the cords). The Nordost, in my opinion, delivered a lower noise floor, increased treble vibrancy, greater transparency, more color, and more dimensionality. The residual grayness heard with the stock cords was replaced by color, vibrancy, and a greater overall musicality. (Editor's Note: Of course it will be argued that when the barrier was down, everyone knew which cords they were hearing.)
One participant thought the Nordost set sounded louder. It wasn't � volume level never changed. But, let's assume that the cords caused a slight change in final volume. If that participant had been able to tell the difference based on his perception of loudness, then he would have scored correctly on the test. But he scored no better than 50/50, just like everyone else.
Given the quality of equipment and recordings, the system sounded wonderful no matter what power cords were used. The Parasounds JC 1s have a distinctly solid-state sound, but it is lightning fast, powerful, brilliant on top, and equally stunning in the bass department. While my reference transport is quite good, the Carmen II delivers a richer sound, with more bass and far greater clarity. (The blur of rapid drum beats heard from my transport was clear without being unnaturally etched on the Carmen II.) As for the ExactPower and the Theta Gen. VIII, I stand by the praise doled out in the reviews posted on this website. (The Talon Khorus X Mk. II sounds quite different than the original issue; it sounds quite wonderful.) The Nordost cords were like the icing on the cake, with the cake satisfying without the frosting.
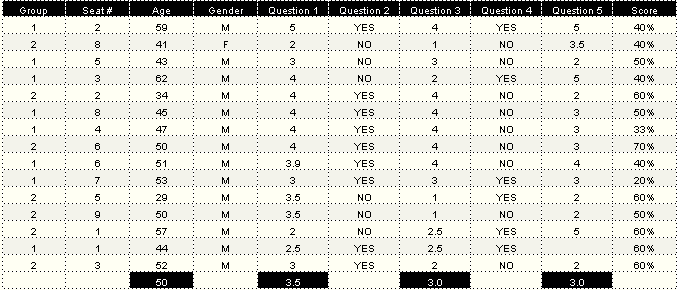
We experienced five last-minute cancellations and two no-shows. We ended up with 9 participants (including myself) in the first group and 6 in the second. One participant was a woman, the rest male. This made for a potential total of 150 responses. In reality, we only received 149, because one participant didn't record a response in one of his ten tests.
The Results
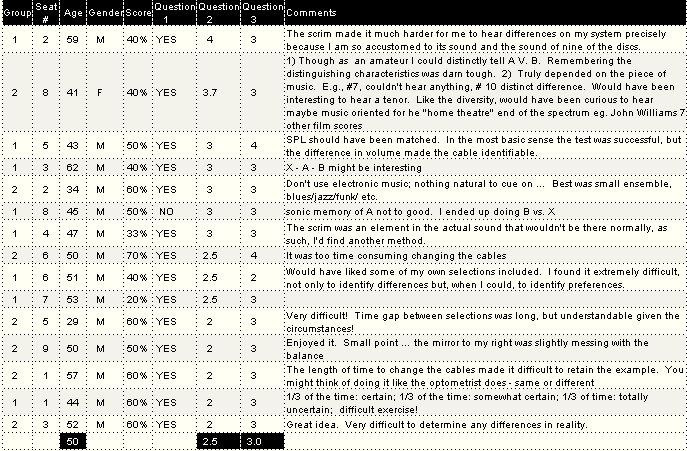
The complete Excel spreadsheet with all test results and participant comments can be accessed herein. After the test, Manny spent quite some time analyzing the results and responses to a post-session questionnaire he composed. I owe much of the following analysis to him.
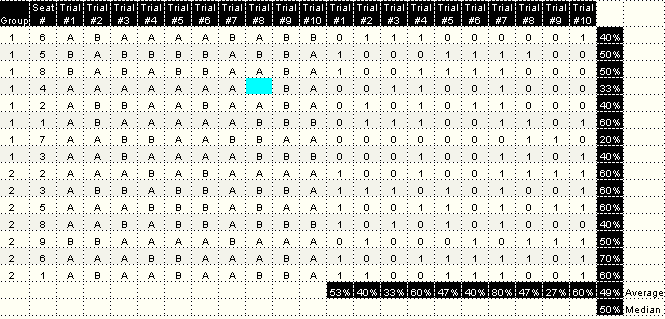
The total number of correct answers was 73 out of 149, which amounts to 49% accuracy. That is no more accurate than flipping a coin, and therefore, no statistically significant detection of power cable differences.
Test participants were asked to rate themselves as to how much of an audiophile they considered themselves to be. The scale was 1 to 5 where 1 = "I'm not an audiophile at all" and 5 = "I'm a hardcore tweak." ("Tweak" is the word Manny chose; I would not have used such terminology, which I find belittling in this context). The self-proclaimed hardcore audiophiles got 48% correct; the rest got 50% correct. Again, no significant differences based on whether or not a listener felt he was an audiophile or not.
Those above the median age of 50 scored 43% as a group; those 50 and younger scored 53% as a group. Those who frequently attend concerts of un-amplified music scored 44%, those who don't scored 50%. Those who play a musical instrument scored 47%, those who don't 50%. The 9 out of 15 participants who have invested in after-market power cords scored 48%.
Twelve of the 15 participants gave themselves a 3 or better on the 1 to 5 scale of degree of audiophile dedication. Half of the listeners gave themselves a 3 or better regarding their belief that they could hear difference between power cords. Those who rated themselves above the median for their perceived ability to discern differences between power cords scored 49%, the same as those who rated themselves below the median.
Those who on the post-test survey felt most strongly that they had heard differences between cords during the test did not perform better than those who rated their abilities at or below the median. Those who thought they did best scored 45%, while those who thought they did so-so or poorly scored 50%.
The participant who scored best in the first group of 9 was a BAAS member who complained afterwards that it took him half the test to just become comfortable with the music and the sound. He rarely listens to classical music, and found the four selections off-putting. He also expressed a desire for more funk and rock-and-roll. Yet he scored the best of the lot in his test group, with 6 out of 10 correct responses.
The participant who scored best in the second group of 6 is a BAAS member who participated in Hone Your Listening Skills. He got 7 out of 10 right. According to Manny, even 7 out of 10 is not high enough to be statistically significant.
On the post-test survey, 14 out of 15 test participants (93%) answered "Yes" to the question, "Do you feel that the test procedure was reasonable in its attempt to answer the question of the audibility of power cords?"
12 out of the 15 participants (80%) felt that the length of the musical selections was "Just right." Two felt they were a little long, and 1 felt that they were a little short.
Participants were 80% correct in their responses to the selection from the Berlioz Requiem. Manny calls this "very close to the threshold between chance and perception. None of the other selections produced responses higher than 60%. This phenomenon correlates with John Atkinson's experience that his participants fared best on massed choral music. If any of us were mad enough to conduct another blind test of this nature, I would choose audiophile recordings of massed choral music for at least 50% of the musical selections. It would be interesting to discover if it would make a difference.
In post-test discussion, several of us noted that we had great difficulty remembering what A had sounded like by the time we got through with X. Several participants said that the way they dealt with this phenomenon was by ignoring A entirely and simply comparing B to X without giving thought to A.
I wish I had tried that. I wish the felt hadn't been there. But I don't know if it would have made a bit of difference.
After each session, Manny privately told individual participants who wished to know how well they had performed on the condition that they wouldn't share the information with anyone in the other group. Needless to say, many of us were dumbfounded. I got only four out of 10 right. Our dog has been licking pie off my face ever since.
Pre-Test Survey:
1) Do you consider yourself an "audiophile?"
2) Have you ever purchased "premium" or "specialty" power cords for you audio equipment?
3) How strongly do you believe that you you can hear differences between "standard" and "premium power cords in audio equipment?
4) Do you currently play a musical instrument?
5) How often do you hear unamplified musical performances?
Test Results:
Post-Test Survey:
1) Do you feel that the test procedure was reasonable in its attempt to answer the question of the audibility of power cords?
2) How large were the differences that you heard? (1 = I heard no differences; 5 = Huge)
3) Do you feel that the length of the musical selections was � (1 = much too short; 5 = much too long)?
Quibbles and Bibbles
It is clear from the above analysis that no matter what background or experience a participant brought to the test, it did not help him or her score better than anyone else. 49% accuracy is 49% accuracy.
There were several acknowledged weaknesses to the test. The number of participants and trials was not very high. Most people sat far from the sweet spot. The ideal situation, which would have allowed participants to audition A and B more than once before trying to identify X, was not possible because the length of time it would have taken to do so would have burned everyone out. (Many members of the second group said they were fried by the time 3:30 PM rolled around.) Switchers failed to turn on both amps three times, and Baci Brown of canine renown further interrupted the flow twice with scratching and barking at outside sounds and a perceived need to pee it all out in the yard. Finally, and perhaps of greatest significance, the time it took to switch cords was longer than the generally accepted 5 second length of human auditory memory. This reduced what Manny terms "the differential sharpness of perception" of participants.
There is, of course, no way to know if a maximum 5 second delay between auditioning A, B, and X would have made a statistical difference. In fact, there is no way to know if we would have scored better if every possible scenario we could think of was exactly as we wished it to be in the best of all possible worlds.
Conclusions
To many in the engineering community, blind ABX is an accepted experimental design. Using the blind ABX protocol, we failed to hear any differences between an assortment of generic power cords and Nordost Valhalla. Therefore, we cannot conclude that different power cords produce a difference using the blind ABX protocol. However, we also cannot conclude that there are no differences. We simply failed to prove that differences can be detected to a statistically significant degree using a blind ABX protocol.
John Johnson, who comes from a scientific background, suggests that if there are differences between cords, they appear to be so subtle that a blind ABX test cannot discern them with small numbers of participants. Failure to discern them could be due in part to the time it took for cable changes, and the possibility that accurate auditory memory is shorter than that. It may be necessary to switch between cords in a much shorter time.
Unfortunately, as John notes, we don't know of a way of accomplishing fast power cable changes, since, unlike interconnects which can be simply switched between A and B with the equipment all still powered on and playing music, changing AC power cords requires turning the equipment off, switching the cords, and then powering them back on.
The test was a grand and noble experiment at best and a bust at worst. Make of it what you will.
Editor's Note: ABX tests are valid and do work. Here is a link to some ABX tests of various types of audio products. In many cases, statistically significant differences could be discerned by participants. In others, no differences could be discerned.
Now, of course, one can dissect an experiment and say, well these 4 people out of 10 participants had good scores, so they could hear the differences. But, no, you have to take all the data together. You can't just pick out the numbers that suit your hypothesis. This would be statistically invalid. Same thing with just looking at one music selection. With statistical random patterns, it is likely that there will be one selection where more participants score correctly than on other selections. If we had enough music selections, there would likely be one where all participants scored perfectly. But, you have to look at all the selections together. That is the purpose of statistics. You may remember the famous monkeys typing randomly concept. If you have enough monkeys, eventually one of them will type all of Shakespeare's works perfectly. To look at only that one monkey might suggest it knew how to type Shakespeare. But, we can't do that and claim good science.
- Jason Victor Serinus -
Magazine Publishing Solutions by